“AI랑 머신러닝이랑 딥러닝이 다른 거예요?”
회사 회의에서 이런 말 들어보신 적 있으신가요?
“이번 프로젝트는 AI 도입이 핵심입니다.”
“머신러닝 모델을 적용해서 예측 정확도를 높여야 해요.”
“딥러닝 기반으로 가야 경쟁력이 있죠.”
분명 비슷한 말 같은데 자꾸 다르게 쓰니까 헷갈리시죠? 저도 처음엔 똑같은 줄 알았어요. 그런데 이 셋은 분명히 다른 개념입니다.
오늘은 비개발자도 한 번에 이해할 수 있도록, 일상 비유로 쉽게 풀어드릴게요.
한 줄로 먼저 정리하면
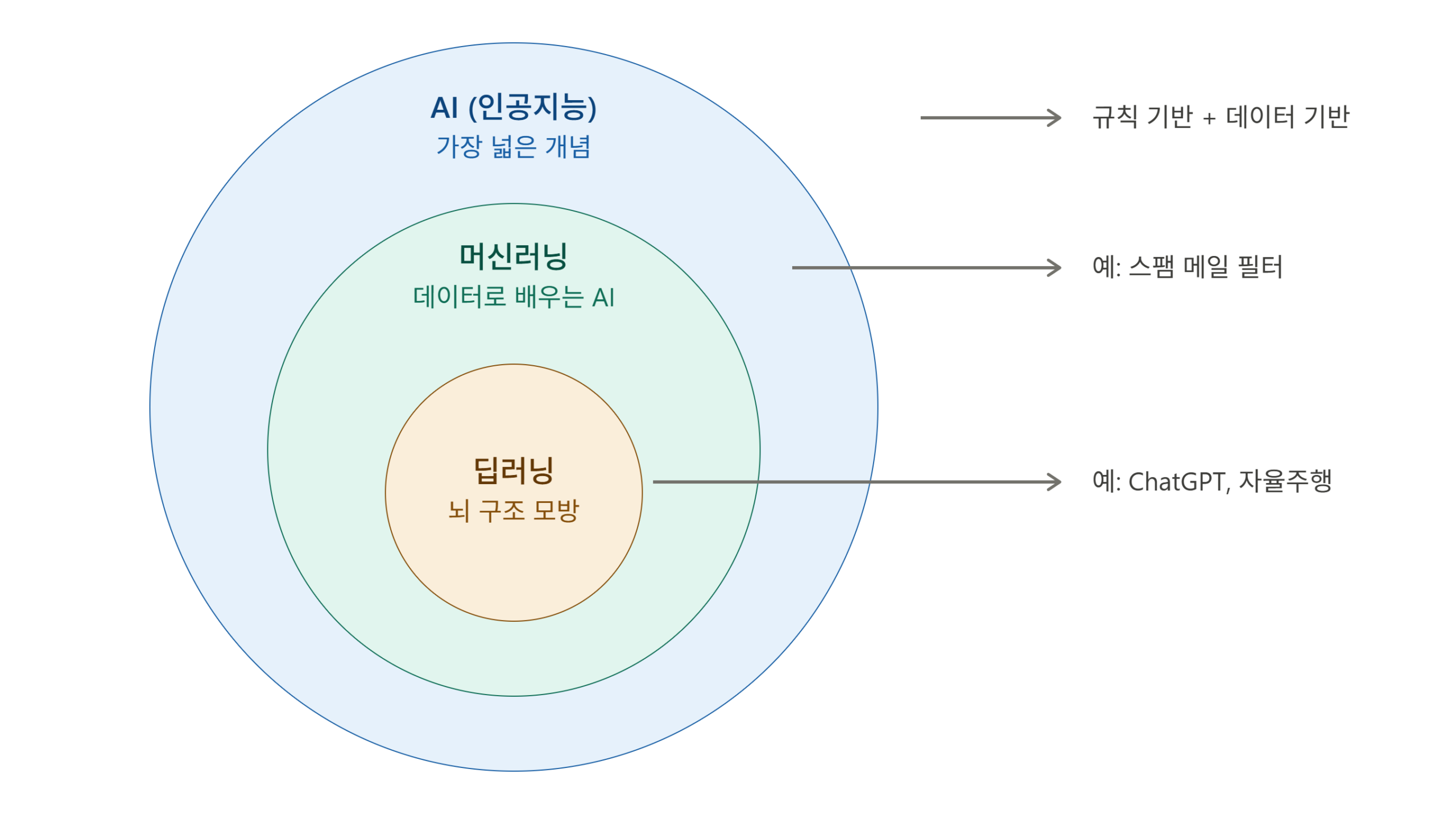
AI ⊃ 머신러닝 ⊃ 딥러닝
네, 이 셋은 포함 관계입니다. 딥러닝은 머신러닝의 한 종류고, 머신러닝은 AI의 한 종류예요.
마치 이런 거죠:
- 음식 (가장 넓은 개념) → AI
- 한식 (음식의 한 종류) → 머신러닝
- 김치찌개 (한식의 한 종류) → 딥러닝
김치찌개는 한식이면서 음식이지만, 모든 음식이 김치찌개는 아닌 것처럼요.
1. AI (인공지능) – 가장 넓은 개념
📖 정의를 쉽게 풀어보면
AI는 “사람처럼 생각하고 판단하는 기계”를 만들려는 모든 시도예요. 1956년에 처음 이 용어가 나왔으니까 무려 70년 된 개념이죠.
🍳 일상 비유로 이해하기
AI를 “똑똑한 비서”라고 생각해보세요. 이 비서는 두 가지 방식으로 일할 수 있어요.
방식 1: 규칙대로 일하기 (Rule-based AI)
- “손님이 오면 → 인사한다”
- “전화벨이 울리면 → 받는다”
- 모든 상황에 대해 미리 정해놓은 규칙대로 행동
방식 2: 경험으로 배우기 (머신러닝)
- 여러 상황을 겪으면서 스스로 패턴을 찾아냄
- 이게 바로 다음에 설명할 머신러닝!
💼 실생활 예시
- 네이버 맞춤법 검사기 – 규칙 기반 AI
- 엘리베이터 자동 운행 – 규칙 기반 AI
- 자판기 – 정해진 규칙대로 동작하는 단순 AI
👉 한마디로, AI = “사람처럼 행동하는 기계 = 모든 종류 다 포함”
2. 머신러닝 – 데이터로 스스로 배우는 AI
📖 정의를 쉽게 풀어보면
머신러닝(Machine Learning)은 “기계가 데이터를 보고 스스로 학습하는 방식”이에요. 사람이 일일이 규칙을 안 짜줘도, 데이터만 많이 주면 알아서 패턴을 찾아냅니다.
🍳 일상 비유로 이해하기
요리를 배우는 두 가지 방법을 생각해보세요.
방법 A: 레시피대로 (규칙 기반 AI)
- “물 500ml를 끓이고 → 라면 넣고 → 4분 30초 기다린다”
- 레시피에 없는 상황이 오면? → 어떻게 해야 할지 모름
방법 B: 어머니 어깨너머로 배우기 (머신러닝)
- 어머니가 100번 요리하시는 걸 옆에서 봄
- “아, 이런 식재료엔 이렇게 하시는구나” 패턴을 익힘
- 새로운 식재료가 와도 비슷하게 응용 가능
이게 바로 머신러닝이에요!
💼 실생활 예시
- 스팸 메일 필터 – 수많은 스팸 메일을 학습해서 새 메일이 스팸인지 판단
- 유튜브 추천 알고리즘 – 내가 본 영상 패턴을 학습해서 비슷한 영상 추천
- 쿠팡 상품 추천 – 내 구매 이력으로 좋아할 만한 상품 예측
- 신용카드 부정사용 탐지 – 평소 사용 패턴과 다르면 자동 차단
👉 한마디로, 머신러닝 = “데이터로 학습하는 AI”
3. 딥러닝 – 사람 뇌를 흉내 낸 머신러닝
📖 정의를 쉽게 풀어보면
딥러닝(Deep Learning)은 머신러닝의 한 종류인데, “사람 뇌의 신경망 구조를 흉내 내서” 학습하는 방식이에요. “딥(Deep)”이라는 이름은 신경망이 여러 층(layer)으로 깊게 쌓여있어서 붙은 거죠.
🍳 일상 비유로 이해하기
강아지와 고양이 사진을 구분하는 일을 시켜본다고 해볼게요.
일반 머신러닝의 방식:
- 사람이 알려줘야 함: “귀가 뾰족하면 고양이, 둥글면 강아지”
- “수염이 길면 고양이일 확률 높음”
- 어떤 특징을 봐야 할지 사람이 가이드라인을 줘야 함
딥러닝의 방식:
- 강아지 사진 10만 장, 고양이 사진 10만 장 그냥 던져줌
- “이게 강아지고, 이게 고양이야. 알아서 찾아봐”
- AI가 스스로 “아, 이런 모양들이 강아지구나”를 깨달음
- 사람이 알려주지 않은 미묘한 특징까지 잡아냄
이게 가능한 이유는 사람 뇌처럼 여러 단계로 정보를 처리하기 때문이에요. 1층에서는 단순한 선과 색을 인식하고, 2층에서는 모양을 인식하고, 3층에서는 “이건 귀구나” 하는 식으로 점점 복잡한 걸 인식합니다.
💼 실생활 예시
- ChatGPT, 클로드, 제미나이 – 모두 딥러닝 기반
- iPhone 얼굴 인식 (Face ID) – 딥러닝
- 자율주행 자동차 – 카메라 영상을 실시간 분석
- 구글 번역 – 문장 전체의 맥락을 이해해서 번역
- 의료 영상 판독 – X-ray, MRI 사진에서 병변 자동 발견
👉 한마디로, 딥러닝 = “뇌 구조를 흉내 낸 머신러닝”
한눈에 비교 정리
| 구분 | AI | 머신러닝 | 딥러닝 |
|---|---|---|---|
| 등장 시기 | 1956년 | 1980년대 | 2010년대 |
| 학습 방식 | 규칙 + 데이터 | 데이터로 학습 | 신경망으로 학습 |
| 데이터 필요량 | 적어도 OK | 많이 필요 | 엄청 많이 필요 |
| 사람의 개입 | 규칙 직접 작성 | 특징 알려줘야 함 | 스스로 학습 |
| 대표 예시 | 맞춤법 검사 | 스팸 필터 | ChatGPT |
그래서 실무에선 어떻게 쓰일까?
📌 예시 1: 회사에서 고객 문의 자동 응답 시스템 만들기
방식 1 – 규칙 기반 AI
- “환불”이라는 단어 포함 → 환불 안내 자동 발송
- “배송” 단어 포함 → 배송 조회 안내
- 👉 빠르고 정확하지만, 예상치 못한 질문엔 못 대응
방식 2 – 머신러닝
- 과거 고객 문의 1만 건과 답변을 학습
- 새 문의가 오면 비슷한 과거 사례를 찾아 답변 추천
- 👉 유연하지만 학습 데이터가 많이 필요
방식 3 – 딥러닝 (예: ChatGPT 활용)
- 문의 맥락 자체를 이해하고 자연스러운 답변 생성
- 고객 감정까지 파악해서 응대 톤 조절
- 👉 가장 똑똑하지만 비용과 시간이 더 듦
📌 예시 2: 사내 데이터로 매출 예측하기
- AI 접근: “작년 12월에 매출 올랐으니 올해도 오를 것”이라는 단순 규칙
- 머신러닝 접근: 과거 5년 데이터에서 계절, 날씨, 이벤트 등을 학습해 예측
- 딥러닝 접근: SNS 트렌드, 뉴스 키워드까지 종합적으로 분석해 예측
마무리: 그래서 뭐가 중요한가?
비개발자 입장에서 가장 중요한 건 이 세 개의 차이를 정확히 아는 것보다, “지금 우리 업무에 어떤 게 필요한가”를 판단하는 것이에요.
- 단순 반복 업무 자동화 → 규칙 기반 AI로도 충분
- 데이터 기반 예측이 필요 → 머신러닝 도입 검토
- 이미지/언어 처리, 복잡한 판단 → 딥러닝 (ChatGPT, 클로드 등 활용)
요즘 ChatGPT, 클로드, 제미나이 같은 도구는 모두 딥러닝의 결과물이에요. 그래서 우리는 사실상 매일 딥러닝 기술을 쓰고 있는 셈이죠.
다음 글에서는 이 딥러닝 시대의 핵심인 “LLM(대규모 언어모델)이 도대체 뭔가?”를 다뤄볼게요. ChatGPT가 어떻게 사람처럼 말을 하는지, 그 비밀을 풀어드립니다.
이 글이 도움 되셨다면 댓글로 어떤 AI 용어가 가장 헷갈리는지 알려주세요. 다음 글 주제로 다뤄볼게요!